There was recently a little tempest in a teapot on Twitter about some measure of how influential a Twitterer you are, which got me thinking about how silly a lot of these measures are. They remind me a lot of early baseball statistics: read one of the early books in the sabermetrics genre, like The Hidden Game Of Baseball, and you’ll find a lot of dudes with limited statistical training taking a little of x, and a little of y, adding it together, and finding that — hey, this looks like a good measure of something; let’s use it! There are worse ways to develop a measure of something, but there are also better ways. Subsequent sabermetricians developed better ways, using rigorous statistics.
These amateur Twitter ranks made me think of Google’s PageRank algorithm, which was based on years of work trying to measure influence in academic journals. The Google problem and the journal problem are quite similar: if a given journal, or a given journal article, have a lot of inbound “links” (that is, citations from other journals), that’s good — but only if the linking journals are themselves highly linked. A bunch of citations from garbage journals, or a bunch of inbound web links from spam sites, shouldn’t contribute anything to your journal’s or your website’s rank.
The math behind the basic PageRank algorithm is simple. Imagine that you’re an infinitely patient web surfer who jumps randomly from page to page: you start on some page, click on every link on that page, and do the same on every subsequent page. If you click on 10,000 links, and 500 of them go to CNN.com, then you’ve spent 5% of your time on CNN. If 1,000 of those links go to NYTimes.com, you’ve spent 10% of your time on the [newspaper: Times]. The PageRank for a given site is the fraction of time that our hypothetical random web surfer spends, in the long term, on that site.
Specifically, imagine a big table listing the probability that one site links
to another:
| CNN | NYTimes | HuffingtonPost | TalkingPointsMemo || CNN | 0.75 | 0 | 0 | 0.25 |
| NYT | 0 | 0.75 | 0.05 | 0.20 |
| HuffPo | 0.35 | 0.40 | 0.20 | 0.05 |
| TPM | 0.20 | 0.30 | 0.10 | 0.40 |
(In Google’s practice, this would be a square table with as many rows and as many columns as there are pages on the Internet. So imagine a table with billions of rows and as many columns.)
The probability in each cell is the probability that the domain in the same row links to the domain in the same column; so for instance,
the probability that CNN links to Talking Points Memo is 0.25; it doesn’t link at all to the [newspaper: Times] or to the Huffington Post.
(These are purely made-up numbers.)
Imagine, again, that we’re a random web-surfer. We start at the [newspaper: Times]’s website, click somewhere, then click another link at random from where we’ve landed. So now we’re two clicks away from wherever we started. What’s the probability that we’d end up at Huffington Post after two clicks? Turns out that we can answer the question if we turn the table above into a mathematical object called a matrix. The matrix version of the table above looks like
![[ [0.75 0 0 0.25] [0 0.75 0.05 0.2] [0.35 0.4 0.2 0.05] [0.2 0.3 0.1 0.4] ]](https://static.stevereads.com/img/transition_prob_matrix.png)
This is called a “transition-probability matrix.” Since every row sums to one — because every page links to some other page, even if the page it links to is itself — it’s also called a “stochastic matrix.” It turns out — via the Chapman-Kolmogorov equation — that the probability of getting from one of those pages to another within two clicks is the square of the transition-probability matrix. Squaring such an odd-looking beast may seem weird, but it’s a well-defined operation called matrix multiplication. The square of that matrix looks like so:
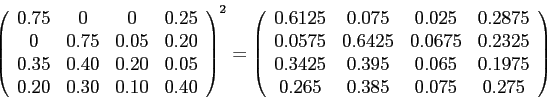
which says that the probability of getting from Talking Points Memo to Huffington Post in two clicks is 0.075. Continue this process through many clicks and you’ll eventually approach what’s called the “stationary distribution” — the long-term probabilities of ending up in any given state, independently of where you started out. In this particular case, the stationary probabilities are
- CNN: about 0.285
- The Times: 0.4
- HuffPo: about 0.057
- TPM: about 0.257
The [newspaper: Times], then, would have the highest PageRank, followed by CNN, TPM, and HuffPo. Again, the interpretation of the PageRank is very simple: the long-term fraction of time that a random [1] web-surfer would spend on your page.
Of course Google needs to modify this basic approach somewhat. One assumes that there’s a lot of “secret sauce” baked into the actual PageRank algorithm — as opposed to this bare skeleton — that allows Google to respond to spammers more effectively.
Regardless, I suspect a Markov-chain approach like PageRank would apply with few modifications to Twitter. Your Twitter rank would go up the more retweets (someone on Twitter essentially forwarding your tweet on to his or her followers) or mentions (someone including your Twitter handle in his or her tweet) you get, but only if the people retweeting or mentioning you were themselves highly ranked. The essential metric would be the fraction of time that a random Twitter surfer would spend reading your tweets.
One might argue that having a lot of followers should increase your Twitter rank. This is debatable: are your followers actually valuable if they’re not mentioning you or voting for your tweets by retweeting them? I could see basing the Twitter rank on followers rather than tweets, in which case the interpretation would be “the fraction of time a random Twitter surfer, jumping from Twitter handle to Twitter handle, would spend on your account.” But that seems less promising than basing it on tweets.
In any case, the point is that PageRank has a simple interpretation based on probabilities. This is in contrast to all the gimmicky Twitter-ranking sites, whose point is to drive traffic to one site or another. It’s like we’re reinventing Google. Right now we’re at the Alta Vista of Twitter: the current competitors are less focused on searching and ranking, more focused on their “portal,” and ultimately less professional than what Google came up with by using actual math.
For much, much more on the mathematical details of PageRank, see Langville and Meyer’s Google’s PageRank and Beyond: The Science of Search Engine Rankings. It’s a gem.
[1] — Specifically, someone surfing according to a Markov chain. This is a very simple way of modeling a sort of random process that has “no memory”: if you tell me the first, second, third, fourth, and fifth pages you clicked on, and ask me to guess what your sixth page will be, I can throw out all the information you gave me apart from the fifth page. Earlier states, that is, don’t matter in prediction of the future; only the most recent state matters.
